SP-4: Local GPT on Secure Documents
Building a Local Retrieval Augmented Generation System with No GPU Required
SP-4 is an experimental local GPT implementation designed for Retrieval Augmented Generation (RAG) that runs entirely on CPU. This system enables you to query your private documents using natural language while maintaining complete data privacy and control.
What is Retrieval Augmented Generation (RAG)?
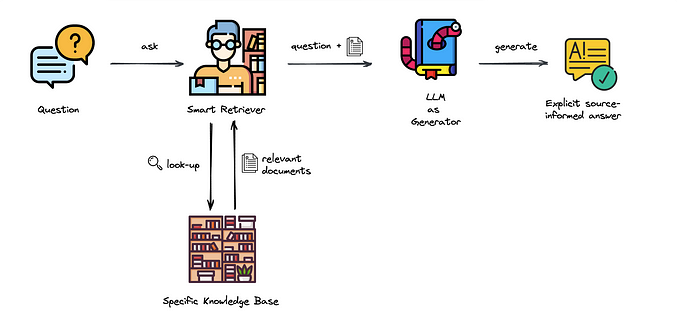
Retrieval-Augmented Generation (RAG) is a technique that enhances large language model outputs by incorporating relevant information from external knowledge sources before generating responses. Rather than relying solely on training data, RAG systems can access and reference specific documents or databases in real-time.
This approach allows us to create powerful, context-aware AI systems without the need to retrain models on custom datasets. We leverage pre-trained models’ generative capabilities while feeding them relevant context from our specific documents, creating what is essentially a custom knowledge assistant.
The key advantage of RAG is that it provides up-to-date, domain-specific information while maintaining the language understanding and generation capabilities of large language models. This makes it particularly valuable for enterprise applications, research, and any scenario where you need AI assistance with proprietary or specialized content.
System Architecture and Workflow
SP-4 implements a sophisticated RAG pipeline using LlamaIndex as the foundational framework. The system follows this workflow:
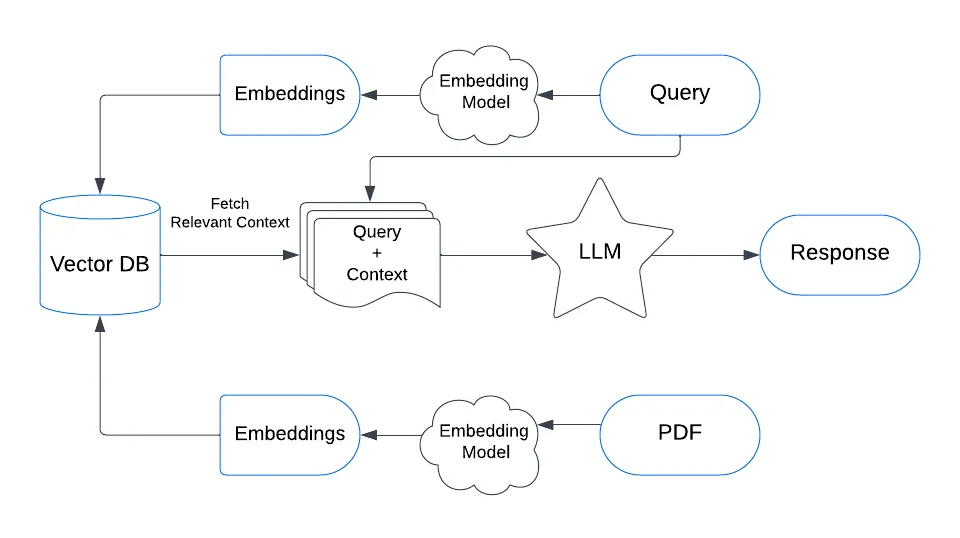
- Query Reception: The system receives a natural language query from the user through a web interface
- Query Embedding: The query is converted into a high-dimensional vector using a sentence transformer model, preserving semantic meaning
- Similarity Search: The system retrieves the most relevant document chunks by computing cosine similarity between the query embedding and stored document embeddings
- Context Assembly: Retrieved content is assembled with the original query to create a comprehensive prompt
- Response Generation: A local language model processes the enhanced prompt and generates a contextually relevant response
This architecture ensures that responses are grounded in your specific documents while leveraging the reasoning capabilities of modern language models.
Technology Stack
The system combines several open-source technologies to create a robust, local-first solution:
- LlamaIndex: Orchestration framework for context-augmented LLM applications
- Sentence Transformers: Embedding model for semantic similarity calculations
- Mistral 7B: Local language model running via llama.cpp for efficient CPU inference
- PostgreSQL with pgvector: Vector database for storing and querying document embeddings
- Gradio: User-friendly web interface for chat interactions
- PyMuPDF: Document processing for PDF text extraction
Installation and Setup
Prerequisites and Environment Setup
Begin by creating an isolated Python environment to avoid dependency conflicts:
python -m venv sp4_env
source sp4_env/bin/activate # Linux/Mac
# or
sp4_env\Scripts\activate # Windows
Core Python Dependencies
Install the required Python packages for the RAG system:
pip install llama-index-readers-file pymupdf
pip install llama-index-vector-stores-postgres
pip install llama-index-embeddings-huggingface
pip install llama-index-llms-llama-cpp
pip install llama-cpp-python
PostgreSQL Vector Database Configuration
Install and configure PostgreSQL with vector extension support:
# Install PostgreSQL
sudo apt update
sudo apt install postgresql postgresql-contrib
# Start PostgreSQL service
sudo systemctl start postgresql
Configure database access and permissions:
# Access PostgreSQL as superuser
sudo -u postgres psql
# Create a new database user
CREATE ROLE sp4_user WITH LOGIN PASSWORD 'secure_password';
# Grant necessary privileges
ALTER ROLE sp4_user SUPERUSER;
# Exit PostgreSQL terminal
\q
# Restart PostgreSQL service
sudo systemctl restart postgresql
Vector Extension Installation
Install the pgvector extension for similarity search capabilities:
# Install development headers (adjust version as needed)
sudo apt install postgresql-server-dev-16
# Clone and build pgvector
git clone https://github.com/pgvector/pgvector.git
cd pgvector
make
sudo make install
Install additional Python database connectivity packages:
pip install psycopg2-binary pgvector asyncpg "sqlalchemy[asyncio]" greenlet
Language Model Setup
Download a quantized language model for efficient CPU inference. For this implementation, we use Mistral 7B in GGUF format:
- Visit the Hugging Face model repository
- Download the
mistral-7b-instruct-v0.2.Q4_K_M.gguffile - Place it in a
./models/directory within your project
Core Implementation
System Architecture and Client Management
The Client class serves as the central orchestrator for all system components:
import gradio as gr
import random
import time
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.llama_cpp import LlamaCPP
import psycopg2
from sqlalchemy import make_url
from llama_index.vector_stores.postgres import PGVectorStore
from pathlib import Path
from llama_index.readers.file import PyMuPDFReader
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.schema import TextNode
from llama_index.core.vector_stores import VectorStoreQuery
from llama_index.core.schema import NodeWithScore
from typing import Optional
from llama_index.core import QueryBundle
from llama_index.core.retrievers import BaseRetriever
from typing import Any, List
from llama_index.core.query_engine import RetrieverQueryEngine
class Client:
def __init__(self):
# Initialize embedding model for semantic similarity
self.embedModel = HuggingFaceEmbedding(model_name='BAAI/bge-small-en')
# Configure local language model
self.llm = LlamaCPP(
model_path='./models/mistral-7b-instruct-v0.2.Q4_K_M.gguf',
temperature=0.1, # Low temperature for focused responses
max_new_tokens=256, # Response length limit
context_window=3900, # Context window size
generate_kwargs={},
model_kwargs={'n_gpu_layers': 0}, # CPU-only inference
verbose=True
)
# Database connection management
self.conn = psycopg2.connect(
dbname='postgres',
host='localhost',
password='your_secure_password',
port='5432',
user='sp4_user'
)
self.conn.autocommit = True
# Initialize vector database
self._setup_vector_database()
def _setup_vector_database(self):
"""Initialize the vector database for document storage."""
with self.conn.cursor() as c:
c.execute("DROP DATABASE IF EXISTS vector_db")
c.execute("CREATE DATABASE vector_db")
# Configure vector store with pgvector
self.vectorStore = PGVectorStore.from_params(
database='vector_db',
host='localhost',
password='your_secure_password',
port='5432',
user='sp4_user',
table_name='document_embeddings',
embed_dim=384 # Dimension for BGE-small-en model
)
This client class manages three critical components:
- Embedding Model: Converts text to vector representations for similarity search
- Language Model: Generates responses based on retrieved context
- Vector Database: Stores and retrieves document embeddings efficiently
Custom Retriever Implementation
The retriever handles the core similarity search functionality:
class VectorDBRetriever(BaseRetriever):
"""Custom retriever for PostgreSQL vector store operations."""
def __init__(self, vector_store, embed_model, query_mode="default", similarity_top_k=2):
"""Initialize retriever with configuration parameters."""
self._vector_store = vector_store
self._embed_model = embed_model
self._query_mode = query_mode
self._similarity_top_k = similarity_top_k
super().__init__()
def _retrieve(self, query_bundle):
"""Execute similarity search and return ranked results."""
# Convert query to embedding vector
query_embedding = self._embed_model.get_query_embedding(query_bundle.query_str)
# Configure vector store query
vector_store_query = VectorStoreQuery(
query_embedding=query_embedding,
similarity_top_k=self._similarity_top_k,
mode=self._query_mode
)
# Execute similarity search
query_result = self._vector_store.query(vector_store_query)
# Format results with similarity scores
nodes_with_scores = []
for index, node in enumerate(query_result.nodes):
score = None
if query_result.similarities is not None:
score = query_result.similarities[index]
nodes_with_scores.append(NodeWithScore(node=node, score=score))
return nodes_with_scores
The retriever performs semantic similarity search by:
- Converting queries to high-dimensional vectors
- Computing cosine similarity against stored document embeddings
- Returning the most relevant document chunks with confidence scores
Document Processing Pipeline
The document processing function handles ingestion and preparation:
def process_documents(client, file_path):
"""Process documents and store embeddings in vector database."""
# Initialize PDF reader
loader = PyMuPDFReader()
documents = loader.load(file_path=file_path)
# Configure text chunking strategy
text_parser = SentenceSplitter(
chunk_size=1024, # Optimal chunk size for context windows
chunk_overlap=20 # Slight overlap to preserve context
)
# Split documents into manageable chunks
text_chunks = []
doc_indices = []
for doc_idx, document in enumerate(documents):
current_chunks = text_parser.split_text(document.text)
text_chunks.extend(current_chunks)
doc_indices.extend([doc_idx] * len(current_chunks))
# Create node objects with metadata preservation
nodes = []
for idx, text_chunk in enumerate(text_chunks):
node = TextNode(text=text_chunk)
source_document = documents[doc_indices[idx]]
node.metadata = source_document.metadata
nodes.append(node)
# Generate embeddings for each text chunk
for node in nodes:
node_embedding = client.embedModel.get_text_embedding(
node.get_content(metadata_mode="all")
)
node.embedding = node_embedding
# Store processed nodes in vector database
client.vectorStore.add(nodes)
print(f"Successfully processed {len(nodes)} document chunks")
This processing pipeline:
- Extracts text from PDF documents
- Splits text into semantically coherent chunks
- Generates vector embeddings for each chunk
- Stores embeddings with metadata in the vector database
User Interface and Query Processing
The main application creates an interactive chat interface:
def create_chat_interface():
"""Create and configure the Gradio chat interface."""
def respond(message, chat_history):
"""Process user queries and generate responses."""
# Initialize retriever with current settings
retriever = VectorDBRetriever(
client.vectorStore,
client.embedModel,
query_mode="default",
similarity_top_k=2
)
# Create query engine with retriever and LLM
query_engine = RetrieverQueryEngine.from_args(
retriever,
llm=client.llm
)
# Generate response using RAG pipeline
response = str(query_engine.query(message))
chat_history.append((message, response))
return "", chat_history
# Configure Gradio interface
with gr.Blocks(theme=gr.themes.Soft()) as interface:
gr.Markdown("# SP-4 Local Document Assistant")
gr.Markdown("Ask questions about your uploaded documents using natural language.")
chatbot = gr.Chatbot()
msg = gr.Textbox(
placeholder="Enter your question here...",
label="Question"
)
clear = gr.ClearButton([msg, chatbot])
# Connect interface events
msg.submit(respond, [msg, chatbot], [msg, chatbot])
return interface
if __name__ == "__main__":
# Initialize system
client = Client()
# Process initial documents
process_documents(client, './data/sample_document.pdf')
# Launch interface
interface = create_chat_interface()
interface.launch(
share=False, # Keep local for privacy
server_name="127.0.0.1",
server_port=7860
)
System Capabilities and Expected Behavior
Once running, SP-4 provides:
Interactive Document Querying: Users can ask natural language questions about uploaded documents and receive contextually relevant answers.
Semantic Search: The system understands the meaning behind queries, not just keyword matching, enabling more sophisticated information retrieval.
Source Attribution: Responses include context about which document sections were used to generate the answer, providing transparency and verifiability.
Privacy Preservation: All processing happens locally, ensuring sensitive documents never leave your system.
Future Development Roadmap
Near-term Enhancements
Streaming Responses: Implement token streaming for real-time response generation, improving user experience during longer responses.
Document Upload Interface: Add a file upload widget to the Gradio interface, enabling dynamic document addition without system restart.
Multi-format Support: Extend document processing beyond PDFs to include Word documents, text files, and web pages.
Advanced Features
Conversation Memory: Implement conversation history to enable follow-up questions and context-aware discussions.
Advanced Retrieval: Incorporate hybrid search combining semantic similarity with keyword matching for improved relevance.
Document Management: Build document indexing and management capabilities for handling large document collections.
Performance Optimization: Implement caching strategies and query optimization for faster response times.
Technical Considerations
Memory Requirements: The system requires sufficient RAM to load the language model (approximately 4-8GB for Mistral 7B) plus additional memory for document processing.
Processing Speed: CPU-only inference is slower than GPU acceleration but provides better accessibility and lower hardware requirements.
Scalability: The PostgreSQL vector store can handle substantial document collections, though query performance may require optimization for very large datasets.
Security: Running entirely locally ensures complete data privacy, making it suitable for sensitive or proprietary documents.
This implementation demonstrates how modern AI capabilities can be deployed locally while maintaining complete control over data and infrastructure, making advanced RAG systems accessible to a broader range of users and use cases.